Discover how a tiered AI architecture—separating high-reasoning planners from efficient executors—maximizes performance while controlling costs in enterprise automation.
The Purpose: Efficiency is a Function of Intent
In the rush to automate enterprise workflows, we often fall into the trap of using a single tool for every task. We treat AI as a monolithic utility, expecting one model to handle everything from complex architectural reasoning to repetitive data entry.
But true operational excellence isn’t about using the most “powerful” model for every minute of the day. It is about alignment. We believe that intelligence should be tiered to match the complexity of the problem. By separating the intent (the plan) from the action (the execution), we create systems that are not just faster, but fundamentally more reliable and cost-effective. This approach respects the reality of cognitive load—both human and machine—ensuring that we don’t waste high-order reasoning on low-order repetition.
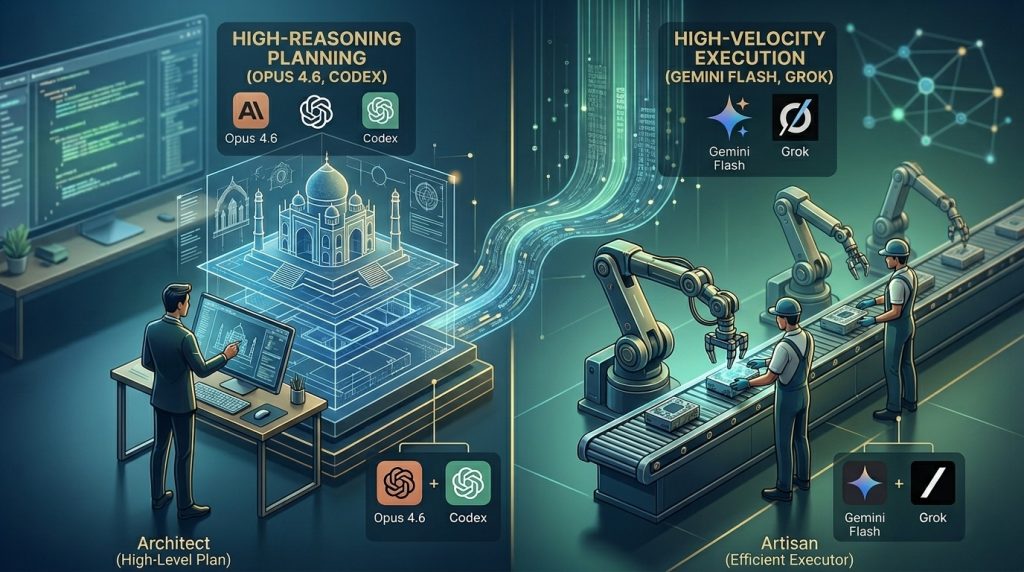
The Strategy: The Architect and the Artisan
To achieve this balance, we employ a “two-tier” orchestration strategy for all scheduled task automation. This methodology mimics a well-run engineering team where a Senior Architect designs the roadmap and a disciplined Junior Engineer executes the sprints.
1. High-Reasoning Planning (The Architect)
We initiate every complex automation with a frontier-grade model, such as Claude 3.5 Opus or Codex. These models possess the dense parameter counts and extensive training necessary to understand nuance, edge cases, and long-term objectives.
The goal here is not speed; it is depth. The “Architect” model consumes the broad requirements and outputs a granular, step-by-step execution plan. This plan acts as the “source of truth,” defining logic gates, data formats, and error-handling protocols.
2. High-Velocity Execution (The Artisan)
Once the plan is solidified, the “Architect” steps back. The daily, hourly, or per-second execution is handed over to high-efficiency models like Gemini 3 Flash or Grok.
These models are the workhorses of the ecosystem. They are optimised for low latency and high throughput. Because they are following a pre-defined, rigid plan generated by a superior reasoning engine, the risk of “hallucination” or logic drift is significantly reduced. They don’t need to wonder why they are doing a task; they only need to focus on how to complete the current step accurately.
The Outcome: Maximum Performance, Minimal Waste
When you decouple planning from execution, the “What” of your automation becomes a lean, high-performance engine. This recipe yields three tangible results for tech-driven organisations:
Cost-to-Value Calibration
The price delta between frontier models and flash models is often several orders of magnitude. By using Opus or Codex only for the initial planning phase (or periodic reviews), and Gemini Flash for the thousands of daily executions, you slash API overhead without compromising the quality of the logic.
Reliability at Scale
Small models often struggle with complex prompts containing too many instructions. By feeding a “Flash” model a specific, narrow slice of a larger plan, you keep the context window clean and the output predictable.
Implementation Guardrails
A typical workflow in this system looks like this:
- Weekly/Monthly: The High-Reasoning model audits the current environment and updates the execution plan.
- Real-time: The Efficiency model triggers tasks—fetching API data, formatting reports, or syncing databases—based on the updated plan.
This tiered architecture allows Indian tech firms to scale their automation horizontally. You no longer have to choose between a “smart” system that is too expensive to run at scale, or a “cheap” system that breaks under complexity. You get both.
Footnotes:
- Anthropic. Claude 3.5 Model Family Capabilities. https://www.anthropic.com/claude
- Google DeepMind. Gemini 1.5 Flash: Efficient Models for High-Volume Tasks. https://deepmind.google/technologies/gemini/flash/
- OpenAI. Codex and the Evolution of Programmatic Logic. https://openai.com/blog/openai-codex
