The Connective Tissue of Architecture
Every distributed system is a series of conversations between isolated services. We spend hours debating compute infrastructure and database schemas, yet the connective tissue routing these conversations gets chosen based on sheer habit. Selecting between Apache Kafka, RabbitMQ, and NATS is an architectural commitment to a specific operational philosophy.
The technology you pick dictates how your application thinks about state, responsibility, and time. Forcing a task-routing problem into a stream-processing engine creates technical debt that breaks your scaling limits. True system resilience begins by matching the software’s internal worldview with your business logic. You are not choosing a tool; you are choosing a data flow model.
The Mental Models of Messaging
To understand how these systems realise their purpose, we must look at how they conceptualise data. Each platform is built around a distinct mental model.
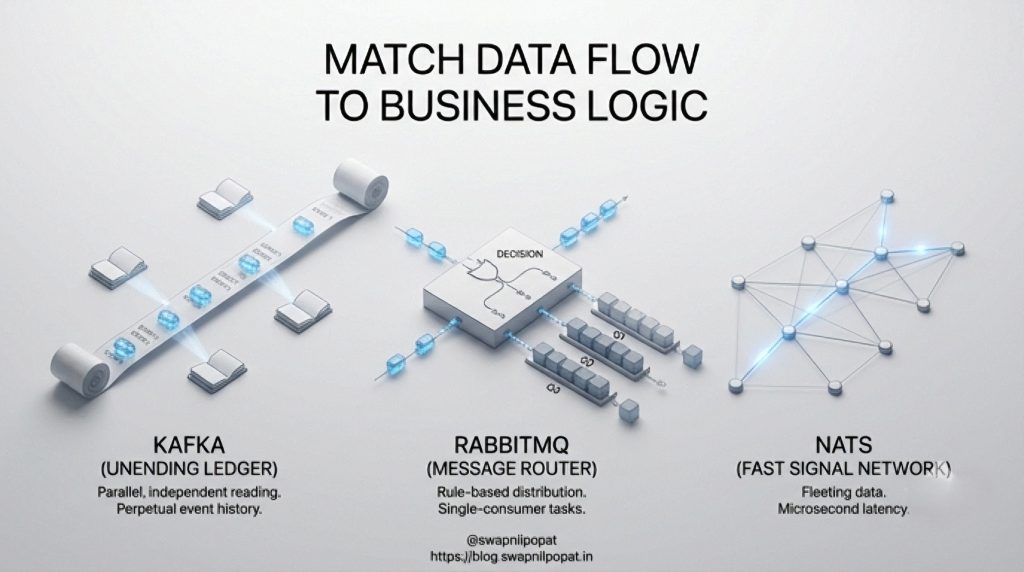
Apache Kafka: The Immutable Ledger
Kafka treats data as historical truth. It operates as an append-only commit log where events are recorded as permanent facts. Consumers do not receive messages; they read from the log at their own pace. This decoupling allows multiple independent downstream systems to process the same dataset in distinct ways. It assumes data has long-term value.
RabbitMQ: The Postal Service
RabbitMQ is a message broker built for task distribution. It takes a message, routes it based on precise rules, and places it in a queue. Once a worker acknowledges processing the job, the broker deletes the message. The focus remains strictly on work distribution rather than data retention.
NATS: The Nervous System
NATS is a messaging fabric prioritising absolute speed and simplicity. It functions like a dial tone for microservices, operating mostly in-memory to deliver near real-time signals. While you can add persistence via JetStream[1], its primary design serves ephemeral, low-latency communication.
Implementation Realities
When you move from whiteboards to production clusters, theoretical differences become hard operational constraints. The “what” of your architecture depends on these practical trade-offs.
Replayability vs Ephemerality
If your business requires regulatory auditing, machine learning model retraining, or event sourcing, Kafka is mandatory. It holds history. RabbitMQ and NATS fire and forget, making them unsuitable for time-travel data recovery.
Throughput vs Latency
Kafka achieves massive throughput by relying on sequential disk I/O and heavy batching. This makes it ideal for log aggregation but poor for individual, real-time user commands. NATS operates in the microsecond latency range, perfect for IoT edge signalling. RabbitMQ sits in the middle, offering balanced performance for general backend tasks.
The Operational Tax
Running Kafka requires serious platform engineering maturity. You must manage partition balancing, retention tuning, and quorum consensus protocols[2]. RabbitMQ introduces some clustering complexity under high load. NATS deploys as a single compiled binary, maintaining a minimal infrastructure footprint.
Aligning Tools with Use Cases
Matching the right tool to the job prevents expensive re-architecting later. Misunderstanding data ownership creates immediate consistency issues.
Building a Data Platform
Choose Kafka for stream processing, telemetry ingestion, and central event backbones. It shines when you need durability and multiple consumers reading the same event.
Orchestrating Work
Choose RabbitMQ for background job processing, payment pipelines, and complex routing fanouts. It excels when you need reliable task execution with fine-grained acknowledgment.
Connecting Microservices
Choose NATS for inter-service communication, device command channels, and control planes. It is the best fit for high-speed, low-overhead network traffic.
The Hybrid Approach
Mature engineering organisations rarely rely on a single solution. A common pattern involves separating command and event channels. RabbitMQ handles the transactional tasks—like processing a user payment—while Kafka broadcasts the resulting state change to downstream analytics services.
Another standard architecture puts NATS at the network edge to ingest high-frequency telemetry from IoT devices. This edge tier then funnels aggregated data into a central Kafka cluster for long-term storage and batch analytics.
The Architect’s Decision Matrix
Before writing any code, evaluate your immediate constraints through a simple sequence. Let the system intent drive the decision.
- Do you need to replay historical events? (If yes, choose Kafka).
- Are you managing a queue of distinct tasks that need individual acknowledgment? (Choose RabbitMQ).
- Is ultra-low latency the primary requirement for service-to-service chatter? (Choose NATS).
- Does your operations team have the bandwidth to manage distributed stateful clusters? (If no, avoid Kafka until absolutely necessary).
Footnotes:
[1] NATS Authors. “JetStream Persistence and Streaming.” NATS Official Documentation. https://docs.nats.io/nats-concepts/jetstream
[2] Apache Software Foundation. “KRaft: Apache Kafka Without ZooKeeper.” Kafka Documentation. https://kafka.apache.org/documentation/#kraft