Implementing Security for Microservices with Policy Agents and OPA
Security design changes the moment you move from a monolith to microservices.
In a traditional application, most traffic enters through one clear front door. You can place authentication, authorisation and rate limits at that edge and get reasonable control. In a microservices environment, that model stops being enough. The API gateway still matters, but it only covers part of the problem. Once a request enters the system, it begins to move across dozens or even hundreds of services. That internal movement is where many teams underestimate risk.
The real issue is simple: in microservices, trust cannot stop at the gateway.
Every internal service call carries business impact. A payment service calling an order service, a customer profile service updating account data, or an admin workflow invoking a deletion endpoint all need to be validated with the same seriousness as external traffic. If internal traffic is treated as implicitly trusted, the architecture becomes fragile. One compromised service can become a pathway to many others.
This is why policy agents have become an important pattern for microservices security. They let teams push security decisions closer to each service rather than sending every decision back to a central authority. In practice, this gives better scale, lower latency and cleaner separation between business logic and access control.
This article looks at how that works, where it helps, where it gets difficult, and how AI is beginning to change the way teams manage security policy in these environments.
Why gateway-only security breaks down in microservices
An API gateway is still useful. It can authenticate users, terminate TLS, apply rate limiting, and reject obvious bad traffic before it reaches internal systems. But it does not solve service-to-service trust.
Once traffic passes the gateway, internal services start making their own calls. A single customer request may trigger an order service, inventory service, pricing service, recommendation engine, payment processor and notification service. At that point, relying on the gateway alone becomes risky for three reasons.
Internal traffic grows faster than external traffic
Most complex business transactions generate far more east-west traffic than north-south traffic. One API call from a mobile app may create ten or twenty internal requests. If those internal hops are not authenticated and authorised properly, the gateway becomes little more than an outer fence.
Network location is a weak trust signal
Older enterprise systems often assumed that if traffic came from inside the network, it was safe. That assumption does not hold in container platforms, hybrid environments or multi-cloud setups. Services get deployed, scaled and moved constantly. IP-based trust becomes difficult to maintain and easy to misuse.
Central checks create latency and bottlenecks
If every service has to call a central IAM server for every decision, the system starts paying a tax on every hop. At small scale, that may seem manageable. At production scale, it becomes a reliability issue. When the central decision point slows down, your applications slow down with it.
This is where decentralised policy enforcement becomes useful.
North-south and east-west security are different problems
It helps to separate the two traffic patterns because they need related but different controls.

North-south traffic
North-south traffic is the flow between external clients and your platform. This includes web apps, mobile apps, partner integrations and public APIs. The API gateway usually handles first-line protection here:
- user authentication
- token issuance or token validation
- rate limiting
- request filtering
- routing
- API-level access control
This layer is visible and well understood by most teams.
East-west traffic
East-west traffic is the flow between internal services. This is harder because it happens continuously and at scale. Service A calls Service B, which calls Service C, and so on. Each of those calls needs two forms of assurance:
- Who is calling?
- Is that caller allowed to perform this action on this resource?
Without those checks, internal calls become a blind spot. That blind spot is dangerous because attackers rarely stop after crossing the perimeter. They try to move laterally. Microservices give them more paths unless trust is controlled carefully.
The decentralised IAM pattern
A central Identity and Access Management system still plays an important role. It can issue identities, manage users, store policies, federate with enterprise directories and support governance. The problem comes when it is used as the runtime decision-maker for every service call.
That sounds neat on paper, but it creates operational strain.
For most teams, the better pattern is to separate policy management from policy enforcement.
- The central platform remains responsible for identity, policy distribution and governance.
- Each service handles enforcement locally through a policy agent.
This is often described as a decentralised IAM or decentralised authorisation model.
The policy does not disappear into every application codebase. Instead, the decision moves closer to the workload. That distinction matters. You are not asking each service team to invent its own security model. You are giving them a local, standard enforcement mechanism that can evaluate centrally defined or centrally distributed policy.
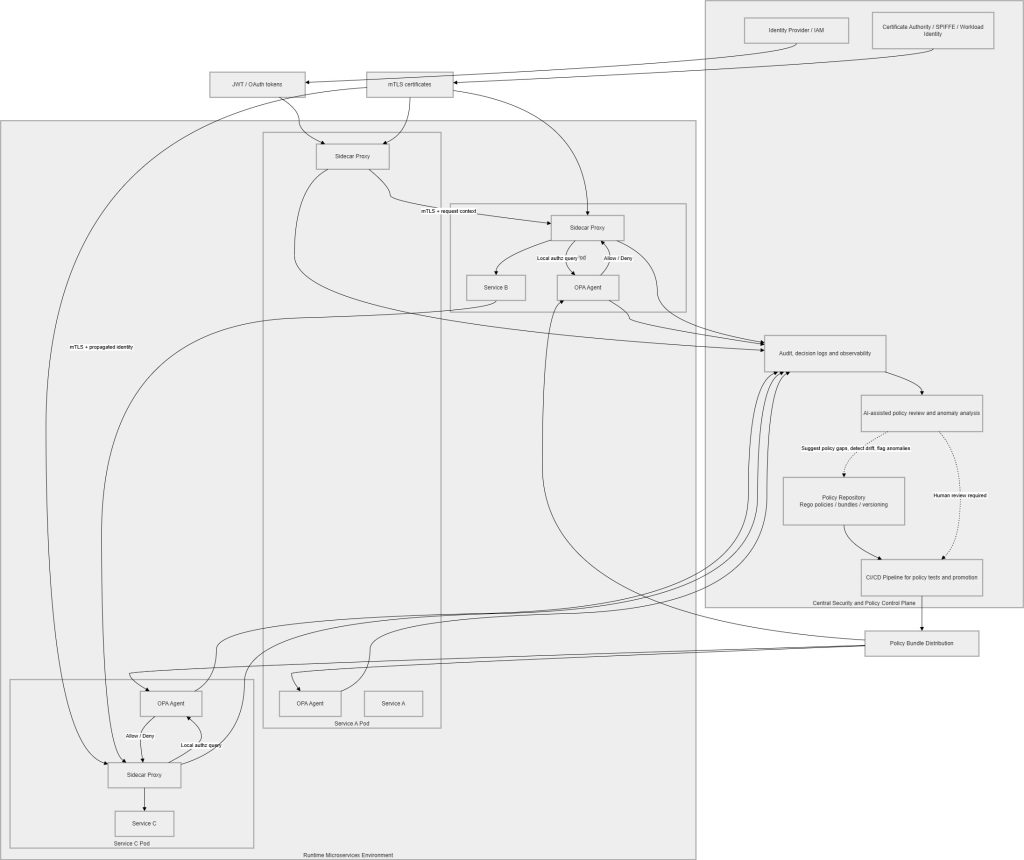
What a policy agent actually does
A policy agent is a small component deployed alongside a service. Its job is to evaluate requests against a set of rules and return a decision such as allow or deny.
In microservices environments, the most widely discussed example is Open Policy Agent (OPA).
OPA is useful because it gives teams a common policy engine across different services and technologies. Whether your microservice is written in Java, Go, Python or Node.js, the authorisation logic does not need to be reimplemented differently in each stack. The application can ask the policy agent for a decision and proceed accordingly.
Why the sidecar model matters
OPA is commonly deployed as a sidecar next to the service, often within the same pod in Kubernetes-based environments.
That design has a few practical advantages:
- policy decisions happen locally
- network round-trips reduce
- the application remains focused on business logic
- policy logic can be updated without rewriting service code
- enforcement becomes more consistent across teams
The sidecar model is not the only option, but it is a common one because it fits how platform teams already package observability, proxies and runtime controls around services.
A practical security workflow in a microservices environment
Let us walk through the request path more carefully. This is where the architecture becomes easier to visualise.
1. The client authenticates at the edge
A user signs in through the API gateway or an identity provider connected to it. After successful authentication, the client receives a token, often a JWT.
That token carries claims about identity and sometimes about roles, permissions, tenant information or session context.
2. The initial request enters the platform
The client sends a request with the JWT attached. The API gateway validates it, applies edge-level controls and routes the request to the first internal service.
At this point, the request has been authenticated at entry. But that is only the beginning.
3. Service-to-service calls pass identity context forward
Suppose Microservice 1 now needs data or action from Microservice 2. It passes the token, or a derived service token depending on the architecture, as part of the downstream request.
This is important because Microservice 2 should not blindly trust Microservice 1 just because it exists inside the platform. It should know both the service identity and, where relevant, the end-user or transaction context.
4. mTLS secures the connection between services
Before authorisation is even checked, the transport layer should be protected. Mutual TLS, or mTLS, allows both sides of the connection to verify each other’s certificates.
This gives two benefits:
- the communication is encrypted
- each service can confirm it is talking to a trusted workload
mTLS does not answer whether a caller is allowed to perform a specific action. It answers whether the caller is a known and trusted participant in the network. That distinction is essential.
A useful way to think about it is this:
- mTLS establishes identity and trust at the connection level
- OPA evaluates permission at the action level
You generally need both.
5. The sidecar or proxy sends the request to the local policy agent
When the request reaches Microservice 2, its sidecar proxy intercepts or evaluates the request flow and sends the relevant attributes to the local OPA agent.
These attributes may include:
- JWT claims
- request path
- HTTP method
- service identity
- resource type
- tenant context
- environment metadata
OPA does not need the whole application state unless the policy requires it. It evaluates only what is relevant to the policy decision.
6. OPA validates and evaluates policy
OPA checks the token, verifies relevant claims and applies policy rules.
For example, a policy may ask:
- Is this token valid and not expired?
- Is the caller from the expected tenant?
- Does the user role permit deletion?
- Is this action restricted to a specific region or environment?
- Is this service allowed to invoke this endpoint at all?
If the answer is allow, the request moves to the microservice. If not, it is rejected before business logic runs.
7. The service executes business logic only after authorisation succeeds
This is one of the strongest benefits of policy agents. Security is handled before the service begins real work. The service code remains cleaner because it does not need to embed scattered if-else access checks across every endpoint and handler.
That sounds tidy, but the larger value is operational. When policy is externalised, teams can review, test and update access rules more systematically.
Why teams adopt policy agents
The appeal of policy agents is not theoretical. They solve real engineering pain in distributed systems.
Better runtime performance than central decision calls
Local decisions are faster than network calls to a central IAM service on every request. This matters when one customer action triggers many downstream calls.
At scale, even small latency savings per hop add up.
Clearer separation of concerns
Microservices work best when each service focuses on a narrow responsibility. Embedding complex authorisation logic into every service works against that. Policy agents let developers keep business logic in the service and access control in a standard evaluation layer.
Consistency across multiple languages and teams
In most enterprises, microservices are not all written in one stack. Some teams use Java and Spring Boot, others use Go, Python or Node.js. Without a common policy layer, each team implements security differently. That leads to drift, duplicate effort and inconsistent enforcement.
OPA helps establish one policy approach across all of them.
Easier policy updates
If rules change, teams do not always need to redeploy the core service code. They can update policy bundles and let the sidecars enforce the new logic. This is particularly useful in regulated environments where approval trails and policy reviews matter.
Better alignment with zero trust ideas
Zero trust is often discussed in broad terms, but in microservices the practical interpretation is simple: no service should be trusted by default, even if it lives inside your own network. Policy agents support that model because every call can be authenticated and authorised explicitly.
What policy agents do not solve on their own
This is where many articles become too neat. Policy agents are useful, but they are not a complete security strategy.
They do not replace identity infrastructure
You still need a proper identity provider, certificate management, token issuance, key rotation and trust distribution. OPA evaluates policy. It does not replace the underlying IAM platform.
They do not remove policy design complexity
Externalising policy is helpful, but writing good policy is not trivial. Poorly designed rules can become hard to understand, hard to test and easy to misconfigure. Teams often move complexity out of code only to recreate it in policy files.
They add operational overhead
Sidecars increase runtime components. That means more configuration, more monitoring, more version management and more platform coordination. If your platform engineering maturity is low, this can feel heavy.
They can create policy sprawl
Once policy becomes easy to add, organisations sometimes create too many overlapping rules without ownership discipline. Then the challenge shifts from enforcement to governance. Who owns the policy? Who reviews it? How do exceptions get handled? How is rollback managed?
These are not reasons to avoid the pattern. They are reasons to implement it with platform thinking, not just tooling enthusiasm.
Design considerations before adopting OPA in microservices
If you are planning this architecture, a few decisions need attention early.
Decide what belongs in tokens and what should be fetched
JWTs are convenient, but teams often overload them with too many claims. Large tokens increase network overhead and can expose stale authorisation context if roles change frequently.
A good rule is to keep tokens focused on stable identity and context claims, while leaving dynamic entitlement decisions to policy evaluation backed by trusted data sources where needed.
Distinguish authentication from authorisation
This is a common architectural mistake. Token validation confirms identity. It does not automatically confirm entitlement. A valid token can still represent a caller who should not perform a given action.
mTLS and JWT validation establish trust. Policy decides permission.
Plan for failure modes
What happens if the policy bundle is outdated? What happens if the sidecar cannot reach the control plane to refresh policies? What happens if the certificate rotation fails?
These questions matter because security systems fail in practice through operational gaps more than through design slides.
Make policy testable
If your teams cannot unit test or integration test policy rules, policy will become tribal knowledge. That leads to production surprises. Policy changes need the same engineering discipline as application code.
Keep service teams involved
Security cannot be dumped on a central team and forgotten. Platform teams can provide the framework, but service owners still need to understand what policy is being enforced around their APIs. Otherwise the model becomes opaque and difficult to troubleshoot.
Where mTLS, service mesh and policy agents fit together
In many real deployments, policy agents are not working alone. They often sit within a broader platform pattern that includes a service mesh.
A service mesh can handle transport concerns such as:
- mTLS between services
- certificate distribution
- traffic routing
- retries and timeouts
- workload identity
OPA or similar policy engines can then handle fine-grained authorisation decisions.
This split is useful because connection trust and action authorisation are different layers. A service mesh is good at proving workload identity and securing communication. A policy agent is good at asking whether this caller, on this path, with this method and this identity context, should be allowed to proceed.
For most teams, combining the two leads to a stronger model than relying on either one alone.
The AI angle: how AI is changing microservices security and policy management
AI is starting to influence this space, but not in the dramatic way marketing often suggests. It is not replacing security architecture. It is changing how teams analyse, generate and monitor policy.
1. AI can help draft policy, but it should not be trusted blindly
Large language models can generate OPA policy examples, explain Rego syntax and suggest access control patterns. This is useful for faster onboarding, especially for teams unfamiliar with policy-as-code.
The trade-off is accuracy. AI-generated policy can look convincing while encoding the wrong logic, missing edge cases or introducing unsafe assumptions. In security, that is costly. A policy that is almost right is often worse than one that fails visibly.
The practical use case is assistance, not autonomy. AI can speed up first drafts, documentation and test case ideas, but policies still need human review, validation and threat-aware thinking.
2. AI can improve policy analysis and drift detection
As policy estates grow, it becomes difficult to understand overlap, redundancy and contradiction. AI-assisted tooling is starting to help teams identify:
- duplicate rules
- unreachable conditions
- over-broad permissions
- inconsistent naming and policy structure
- likely privilege escalation paths
This is valuable because policy debt accumulates quietly. AI can help surface patterns that humans may miss across hundreds of services.
3. AI strengthens anomaly detection around service behaviour
Microservices generate large volumes of telemetry: service calls, tokens, certificates, denials, retries and unusual traffic paths. AI-based detection models can help flag suspicious lateral movement or behaviour that deviates from normal traffic patterns.
For example, if a service that normally reads customer data suddenly begins invoking admin-level endpoints across environments, that pattern deserves scrutiny. Traditional rules can catch some of this. AI-based analysis can improve detection where normal baselines are complex.
Still, this works best as a supporting layer. It should not replace deterministic controls like mTLS, least privilege and explicit authorisation policy.
4. AI raises the stakes for policy quality
AI also changes the threat side. Attackers can use AI to automate reconnaissance, generate phishing flows, analyse exposed APIs and probe for inconsistent access controls faster than before. That makes loose internal trust models even riskier.
In other words, AI is not only helping defenders write policy. It is also making poorly secured microservices easier to exploit at scale.
5. AI governance will itself need policy enforcement
As organisations add internal AI services, model gateways and retrieval systems, they create new east-west traffic patterns. AI applications often access sensitive documents, customer data and internal tools. Those calls need the same policy discipline as any other microservice.
This is becoming a practical issue already. Teams building AI assistants inside enterprises are discovering that model access, prompt handling, retrieval permissions and downstream tool use all require clear service-level authorisation controls. Policy agents fit naturally into that future.
Common implementation mistakes
Teams usually struggle less with the idea and more with execution. A few mistakes come up repeatedly.
Treating internal traffic as trusted by default
This is the fastest way to create lateral movement risk. Internal traffic should be verified, not assumed safe.
Pushing too much policy logic into application code
That makes updates slow and inconsistent. It also creates different security behaviour across teams.
Writing policies without ownership
If nobody owns a policy domain, no one knows who can approve changes or verify intent.
Confusing coarse-grained roles with real authorisation
Simple role checks work for small systems. They break down when you need tenant-aware, resource-aware or context-aware decisions.
Ignoring observability
If you cannot see why a request was denied, support and engineering teams will bypass the controls rather than fix them. Decision logs and clear audit trails matter.
Adopting AI-generated policy without review
This is becoming a new risk. Fast policy generation is tempting, but security logic must be tested and reviewed with the same rigour as production code.
A practical adoption path
Most teams should not try to retrofit the entire estate at once.
A more workable path looks like this:
Start with high-risk service boundaries
Focus first on services handling payments, customer identity, admin functions or sensitive data movement. Secure the highest-value paths before chasing full coverage.
Standardise transport security
Get mTLS and workload identity right. Without that foundation, policy decisions sit on weak trust signals.
Introduce policy-as-code for a small set of critical decisions
Do not encode every possible rule from day one. Start with meaningful authorisation checks that are currently inconsistent or risky.
Build testing and rollout discipline early
Create policy review, test coverage, versioning and rollback processes before policy volume grows.
Add observability and auditability
Track allow and deny decisions, policy versions and enforcement points. Security controls that cannot be explained are difficult to operate.
Use AI carefully where it adds leverage
AI is useful for documentation, policy review support, test generation and anomaly analysis. It is less useful as an unsupervised security architect. Use it to improve team productivity, not to replace accountability.
Final takeaway
Securing microservices means accepting that the perimeter has moved inward.
The gateway still matters for north-south traffic, but it cannot carry the full burden once requests begin moving between services. In a distributed architecture, every internal hop needs trust and every sensitive action needs authorisation. That is why policy agents have become such a practical pattern.
By placing a local policy engine such as OPA alongside each service, teams can enforce decisions closer to the workload, reduce dependence on central runtime checks, and keep business code cleaner. Combined with mTLS, this creates a stronger model for service-to-service trust.
The trade-off is operational discipline. Policy agents do not remove complexity; they move it into a more manageable and auditable form. That only works if teams invest in policy design, testing, observability and ownership.
AI will influence this space more and more, especially in policy generation, analysis and anomaly detection. But the fundamentals remain unchanged: explicit trust, least privilege, local enforcement and good engineering judgement.
For most organisations building serious microservices platforms, that is the direction worth taking.