
Inter-Service Communication in Microservices: Service Mesh vs Message Brokers
Distributed systems do not fail because services exist. They fail because communication between those services becomes hard to reason about at scale.
Once an application is split across containers, pods, clusters, or regions, service-to-service communication stops being a simple coding concern. It becomes an architectural concern. Teams now have to deal with latency, retries, authentication, service discovery, version drift, telemetry, queue backlogs, and partial failures. This is where two patterns become central: service mesh and message brokers.
They solve different problems.
A service mesh helps manage direct, real-time service-to-service calls. A message broker helps manage asynchronous communication where services should not depend on each other being available at the same moment.
Both are useful. Both add operational weight. The real question is not which one is better. It is which one fits the communication pattern, failure tolerance, and operating model of your system.
Why inter-service communication becomes the real system
In a monolith, communication is mostly in-process. Function calls are fast, local, and easy to trace.
In microservices, the same interaction may involve:
- network hops
- DNS or service discovery
- authentication and authorisation
- timeouts and retries
- traffic policies
- observability pipelines
- schema compatibility
- failure handling across service boundaries
That changes the nature of design.
A simple business action such as “show pizza menu” may involve:
- an API gateway or ingress layer
- a menu service
- an authentication or user-profile service
- a pricing or promotion service
- a telemetry pipeline
- security controls between services
What looks like one request to the user may be several internal calls. If each team handles communication differently, the system becomes difficult to secure, monitor, and debug. That is why mature distributed systems move communication concerns into shared infrastructure patterns.
Two core patterns at a glance
| Pattern | Best suited for | Communication style | Strength | Common risk |
|---|---|---|---|---|
| Service Mesh | Service-to-service API calls | Synchronous | Policy, security, traffic control, observability | Added operational complexity and latency overhead |
| Message Broker | Events, tasks, decoupled workflows | Asynchronous | Reliability, buffering, decoupling, resilience | Ordering, duplicate handling, eventual consistency |
A good architecture often uses both.
For example:
- Service mesh for request-response calls between APIs
- Message broker for order events, notifications, inventory updates, fraud checks, and downstream processing
The service mesh pattern
A service mesh is an infrastructure layer that manages communication between services without forcing every team to write that logic in application code.
Instead of embedding traffic control, retries, mutual TLS, telemetry, and service policy inside each microservice, these concerns are handled by the mesh.
This matters in organisations where multiple teams are building services independently. Without a common communication layer, each service tends to implement its own network logic. That creates inconsistency, security gaps, and debugging pain.
What a service mesh actually does
A service mesh commonly handles:
- service-to-service authentication
- encrypted communication using mTLS
- traffic routing rules
- retries and timeouts
- circuit breaking
- policy enforcement
- metrics, logs, and traces
- service identity
- canary and blue-green traffic control
The biggest benefit is consistency. Teams can focus on business behaviour while the mesh handles communication controls in a standard way.
Core architecture: data plane and control plane
A service mesh is usually understood in two parts.
Data plane
The data plane is made up of proxies, often deployed as sidecars alongside each service instance.
These proxies:
- receive outbound requests from the service
- receive inbound requests before they reach the service
- apply routing and security policies
- emit telemetry
- enforce communication rules
In practical terms, traffic goes through the proxy, not directly from one application process to another.
Control plane
The control plane is the management layer.
It does not handle application traffic directly. Instead, it:
- distributes configuration to proxies
- defines which services can talk to each other
- manages certificates and trust
- updates routing rules
- supports service discovery
- centralises policy and telemetry behaviour
If the data plane is the execution layer, the control plane is the policy and coordination layer.
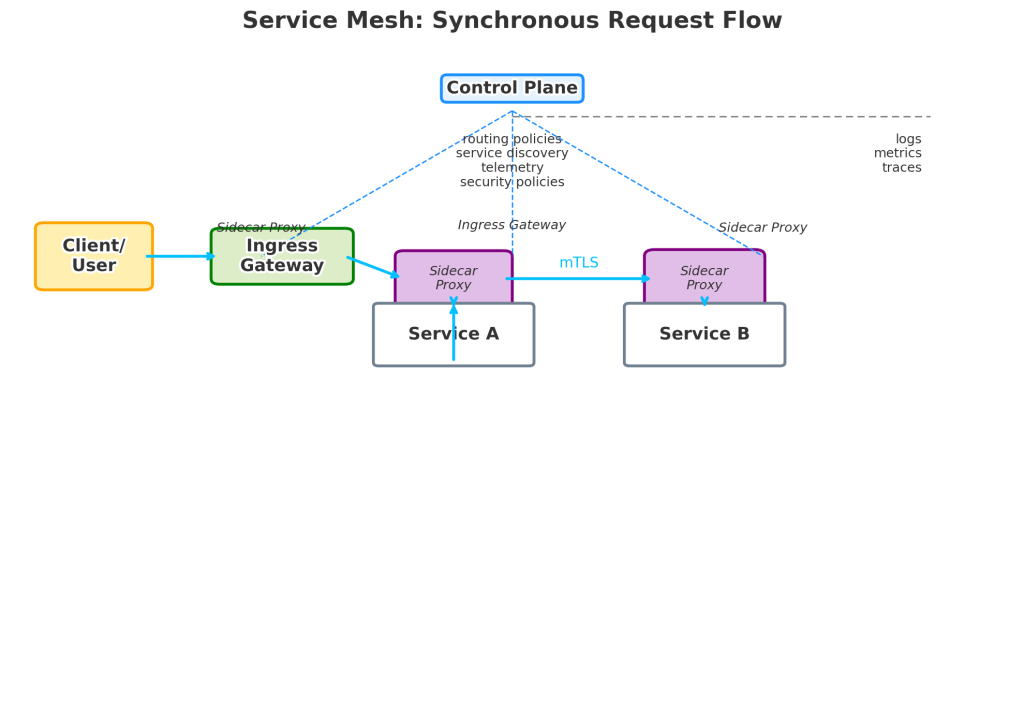
Service mesh request flow: a practical example
Consider a mobile app requesting a pizza menu.
The request path usually looks like this:
- Client request enters through the ingress layer
- The mobile app sends a request to the platform.
- An ingress gateway or ingress controller receives it.
- Ingress forwards traffic to the target service proxy
- The request is routed to the proxy attached to the Pizza Menu service.
- The proxy applies policy checks
- Token validation
- Access rules
- Rate limits
- Traffic rules
- Telemetry capture
- The request is passed to the Pizza Menu service
- The service processes the request.
- It may realise it needs user or authentication context from another service.
- The service calls its local sidecar proxy
- Rather than reaching out directly, the service hands the request to its sidecar.
- The proxy discovers the destination service
- The sidecar checks routing and service discovery information provided by the control plane.
- Secure service-to-service communication happens
- The request is sent to the target service’s sidecar using mTLS.
- The second proxy enforces inbound policy
- It validates identity and traffic rules before passing the request to the target service.
- The response returns through the same controlled path
- Response flows back via proxies, ingress, and then to the client.
What this gives you in practice
Instead of every team implementing this logic separately, the mesh provides:
- standard security between services
- central policy control
- traffic shaping without code changes
- richer tracing across request paths
- easier debugging of latency and failure points
Where it tends to break down
A service mesh is useful, but not free.
Common constraints include:
- Operational overhead: running and upgrading the mesh can be demanding
- Learning curve: teams must understand networking, policies, certificates, and observability concepts
- Latency cost: each proxy hop adds overhead, even if small
- Debugging complexity: issues can sit in application code, proxy config, mesh policy, or the ingress path
- Resource consumption: sidecars use CPU and memory in every pod
For small systems, this can be too much machinery. For larger platforms with many teams, it often becomes worthwhile.
Message broker pattern
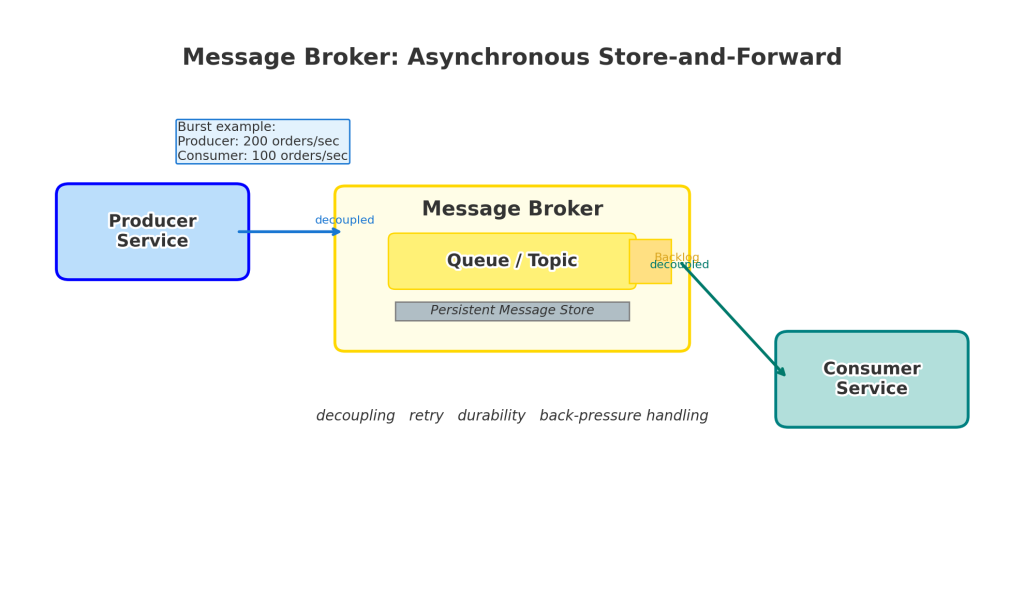
A message broker supports asynchronous communication between services.
Instead of Service A calling Service B and waiting for a response, Service A sends a message to a broker. Service B processes that message when it is ready.
That sounds simple, but it changes the reliability model of the system.
The sender and receiver no longer have to be available at the same time. They no longer need the same processing speed. They no longer need tight runtime coupling.
How it works
At a basic level:
- a producer creates a message
- the message is sent to a broker
- the broker stores it in a queue or topic
- a consumer reads and processes it
- acknowledgements, retries, and dead-letter handling may apply
This is often described as store and forward.
Why this matters
Suppose a Sales service is receiving 200 orders per second, but the Inventory service can handle only 100 per second.
Without a broker:
- Inventory becomes a bottleneck
- Sales may face timeouts
- the user-facing flow may degrade
- upstream services may fail under back-pressure
With a broker:
- Sales publishes order messages
- the broker stores the excess messages
- Inventory consumes them at its own pace
- the system absorbs the spike without immediate failure
This is one of the most practical reasons message brokers are widely used in enterprise systems.
Message brokers are not just queues
In many teams, brokers are reduced to “a queue in the middle”. That understates their architectural role.
A message broker can provide:
- buffering during traffic spikes
- decoupling of producers and consumers
- durable persistence of messages
- retries after temporary failure
- fan-out to multiple downstream consumers
- event distribution across systems
- back-pressure handling
- load smoothing across uneven workloads
Depending on the platform, brokers may support:
- point-to-point queues
- publish-subscribe topics
- consumer groups
- ordered streams
- replay of events
- dead-letter queues
- partitioning for scale
What teams gain
A broker is useful when:
- downstream systems are slower than upstream systems
- consumers may be temporarily unavailable
- business workflows can tolerate eventual consistency
- multiple systems need the same event
- processing should happen independently of the user request path
What teams must handle
Asynchronous design solves one class of problems and introduces another.
Typical challenges include:
- duplicate message delivery
- out-of-order processing
- idempotency requirements
- replay side effects
- event schema evolution
- operational backlog growth
- harder end-to-end tracing
- eventual consistency confusing business users
This is the trade-off. A broker improves resilience and decoupling, but the application model becomes more complex.
Service mesh vs message broker: the decision logic
This choice becomes clearer when framed around communication intent.
Use a service mesh when:
- the caller needs an immediate response
- the interaction is request-response by nature
- traffic policies need central control
- service identity and mTLS matter
- observability of direct service calls is a priority
- teams want consistent retries, routing, and security across APIs
Use a message broker when:
- the sender should not wait for the receiver
- workload smoothing is necessary
- downstream systems process at different speeds
- temporary receiver downtime should not break the sender
- one event may trigger multiple consumers
- eventual consistency is acceptable
Use both when:
- the platform has direct API calls and background workflows
- synchronous interactions feed asynchronous processing
- a user action needs a fast acknowledgement, while heavier downstream work happens later
A common pattern looks like this:
- API request handled through ingress and service mesh
- business service performs immediate validation
- service responds quickly to the user
- service emits an event to a broker for downstream processing
- billing, notifications, analytics, and inventory update asynchronously
That combination often gives the best balance of responsiveness and resilience.
Key capabilities gained across both patterns
Rather than listing features in isolation, it is more useful to look at what these patterns change for platform teams.
1. Observability
Both patterns improve visibility, though in different ways.
Service mesh helps with:
- per-request traces
- latency analysis between services
- policy enforcement visibility
- golden signals such as error rate and response time
Message brokers help with:
- queue depth and consumer lag
- failure and retry visibility
- processing throughput
- backlog build-up trends
What matters more is operational interpretation. More telemetry does not automatically mean more clarity. Teams need alerting, ownership, and dashboards tied to real service risk.
2. Service discovery
In dynamic environments, services move.
- pods restart
- instances scale up or down
- IP addresses change
- routing rules evolve
A service mesh makes discovery and routing more controlled. Brokers reduce the need for direct discovery between producer and consumer altogether.
3. Security
This is often where architecture decisions become easier to justify.
With a service mesh, you can enforce:
- service identity
- encrypted service-to-service traffic
- fine-grained traffic rules
- namespace or workload-level access policies
With brokers, you can enforce:
- who can publish
- who can consume
- topic or queue permissions
- message retention and auditing controls
The real value is not just security features. It is removing ad hoc, inconsistent implementations across teams.
Failure modes architects should plan for
Distributed systems behave well in presentations and badly in production if failure modes are ignored.
Common service mesh failure modes
- bad routing configuration causing traffic loss
- certificate issues breaking service communication
- retry storms increasing downstream load
- misconfigured timeouts leading to cascading failure
- proxy resource overhead affecting application pods
- observability noise masking the real incident
Common message broker failure modes
- unbounded queue growth
- poison messages repeatedly failing
- duplicate delivery causing repeated business actions
- consumers falling behind after traffic bursts
- schema changes breaking downstream processing
- hidden backlog delaying business outcomes without obvious user-facing errors
Practical mitigations
- define timeout and retry budgets clearly
- treat idempotency as a design requirement, not an afterthought
- use dead-letter handling deliberately
- monitor queue depth, lag, and retry volume
- version message schemas carefully
- test partial failure scenarios, not only happy paths
- keep ownership clear for communication infrastructure
Architecture patterns that work well in the real world
Pattern 1: Synchronous front door, asynchronous backend
Best when users need a fast response but not every downstream action must finish immediately.
Example flow
- user places order
- Order service validates request via service mesh
- order accepted response returned
- order event published to broker
- inventory, notification, billing, analytics process independently
Why teams like it
- fast user experience
- fewer cascading failures
- downstream services can scale independently
Pattern 2: Mesh for east-west traffic inside the platform
Best when many internal APIs need policy control.
Useful for
- authentication between services
- zero-trust internal networking
- standard observability
- release strategies such as canary traffic splits
Pattern 3: Broker for domain events and workload buffering
Best when different systems operate at different speeds or need loose coupling.
Useful for
- order processing
- payments workflows
- shipment updates
- fraud analysis
- audit and activity pipelines
The influence of AI on inter-service communication
AI is not replacing these patterns. It is increasing the need for them and changing how they are operated.
As AI features move into business systems, service communication becomes more unpredictable. Request patterns shift. Latency becomes less stable. Some AI workloads are synchronous and user-facing, while others are asynchronous and compute-heavy. That makes the distinction between mesh-managed traffic and broker-managed workloads more important, not less.
Where AI changes the architecture
1. AI introduces uneven workloads
AI-driven services often have variable execution time.
Examples include:
- document extraction
- recommendation generation
- fraud scoring
- summarisation
- agent workflows calling multiple internal services
Some requests return in milliseconds. Others take several seconds or longer. This makes direct synchronous chaining risky if everything is kept on the request path.
Implication:
Teams increasingly use:
- service mesh for low-latency control-plane and API calls
- message brokers for non-immediate AI processing tasks
2. AI increases observability requirements
Traditional service monitoring is not enough when AI is part of the flow.
Teams now need to understand:
- which service called which model
- latency added by model inference
- fallback behaviour when models timeout
- token or compute cost per workflow
- downstream impact of model errors
A service mesh helps with request tracing between services. Brokers help track asynchronous AI jobs and backlogs. Together, they provide a more complete operational picture.
3. AI makes back-pressure more visible
Inference systems can be expensive and capacity-limited.
If an upstream service sends requests faster than model-serving infrastructure can handle them, one of two things happens:
- synchronous paths slow down or fail
- asynchronous queues absorb load and recover gradually
This is where brokers become especially useful for:
- batch inference
- enrichment pipelines
- document processing
- recommendation refresh jobs
- event-driven AI workflows
4. AI pushes teams towards stronger policy controls
AI-enabled systems often touch sensitive data.
That raises questions such as:
- which service is allowed to send data to a model endpoint
- what data should be masked before transmission
- how internal traffic should be encrypted
- how prompts, outputs, and metadata should be logged
A service mesh can help enforce communication security and policy boundaries. It will not solve data governance on its own, but it gives teams a cleaner foundation for doing so.
5. AI-assisted operations will change day-to-day management
AI is also affecting how teams run these systems.
It can support:
- anomaly detection in traces and metrics
- prediction of queue growth and consumer lag
- smarter incident triage from logs and telemetry
- policy recommendation based on traffic patterns
- failure correlation across services and brokers
That sounds promising, but there is a practical caution: AI can suggest likely causes, not guarantee them. Communication infrastructure still needs clear ownership, sane defaults, and tested failure handling.
A useful rule here
Use AI to improve visibility and operational judgement. Do not use it as a substitute for architecture discipline.
Choosing the right pattern: a practical checklist
If you are deciding between a service mesh, a broker, or both, ask these questions.
If the answer is “yes”, lean towards a service mesh
- Does the caller need an immediate response?
- Do we need uniform mTLS and service identity?
- Do teams need central traffic and policy control?
- Are direct API calls multiplying across many services?
- Do we need canary routing or traffic shaping without code changes?
If the answer is “yes”, lean towards a message broker
- Can the work happen later?
- Do producer and consumer run at different speeds?
- Should sender and receiver be decoupled?
- Do we need buffering during spikes?
- Can the business process tolerate eventual consistency?
- Do multiple downstream systems need the same event?
If many answers are “yes” on both sides
That usually means the platform needs both patterns, each for the job it is suited to.
Implementation guidance for teams starting out
Avoid jumping straight to tooling choices. Start with communication behaviour.
Step 1: classify service interactions
Split interactions into:
- request-response
- event-driven
- command-driven
- batch or long-running processing
This prevents teams from using synchronous APIs for work that should be asynchronous.
Step 2: define failure expectations
For each interaction, decide:
- what timeout is acceptable
- whether retries are safe
- whether duplicate processing is acceptable
- whether eventual consistency is acceptable
- what happens when the downstream system is unavailable
Step 3: standardise cross-cutting concerns
Use shared patterns for:
- authentication
- encryption
- logging and tracing
- schema management
- retry and dead-letter strategy
- idempotency handling
Step 4: keep the rollout proportionate
Do not introduce a full service mesh only because it is fashionable. Do not introduce a broker only because teams want “event-driven architecture”.
Adopt these patterns when the communication problem is real enough to justify the operating cost.
Final takeaway
Service mesh and message brokers are not competing answers to the same question. They address different forms of communication in distributed systems.
Use a service mesh when the system needs controlled, secure, observable, synchronous service-to-service traffic.
Use a message broker when the system needs decoupling, buffering, reliability, and asynchronous processing across uneven workloads.
In modern platforms, especially those beginning to integrate AI workloads, the stronger architectural move is often not choosing one over the other. It is being clear about which communication path belongs on the request path, which one should be decoupled, and what operational burden the team is willing to carry.