
Digital Twin Architecture: Components, Patterns, and Implementation Realities
A digital twin is often described too neatly: a virtual representation of a physical asset, process, or system. That is directionally correct, but not very useful when you are trying to design one.
In practice, digital twin architecture is less about drawing a polished system diagram and more about answering difficult questions early. What exactly are you modelling? Which decisions should the twin support? How fresh does the data need to be? What happens when sensor data is incomplete, delayed, or wrong? Who owns the model once it moves from pilot to operations?
Those questions matter because many digital twin programmes fail for familiar reasons. The model is too ambitious, the data foundation is weak, the integration cost is understated, and the business case depends on benefits that no operating team can measure. The result is a visually impressive prototype that never becomes part of day-to-day decision-making.
A good digital twin architecture avoids that trap. It is designed around operational use, bounded scope, and clear decision value. The twin does not need to mirror reality perfectly. It needs to be reliable enough, timely enough, and useful enough for a specific purpose.
This article breaks down digital twin architecture from that practical angle: the core layers, the main architectural patterns, the trade-offs involved, and the issues that tend to surface at scale.
Start with the job of the twin, not the diagram
Before choosing platforms, protocols, or cloud services, define the job of the twin.
That job usually falls into one or more of these categories:
- monitoring current state
- detecting anomalies
- predicting failure or performance drift
- simulating future scenarios
- optimising operations
- supporting remote diagnostics
- improving design through operational feedback
These are not interchangeable. A twin used for live condition monitoring has different requirements from one used for engineering simulation. The first may need near-real-time telemetry, event processing, and alerting. The second may depend more on historical data quality, asset configuration history, and model calibration.
This is where many architectures become bloated. Teams try to support real-time observability, predictive maintenance, closed-loop control, and fleet-wide optimisation in the first release. That usually creates a system that is expensive to integrate and difficult to trust.
A better approach is to define the smallest useful twin. For example:
- a machine-level twin for condition monitoring
- a line-level twin for throughput analysis
- a building twin for energy optimisation
- a fleet twin for maintenance planning
- a supply chain twin for scenario analysis
The architecture should follow that scope. If the use case is narrow, the architecture can stay lean. If the use case spans engineering, operations, and service, the architecture needs stronger governance and model discipline.
What a digital twin architecture actually includes
At a high level, most digital twin architectures have six working layers. The names vary by vendor and industry, but the underlying responsibilities remain similar.
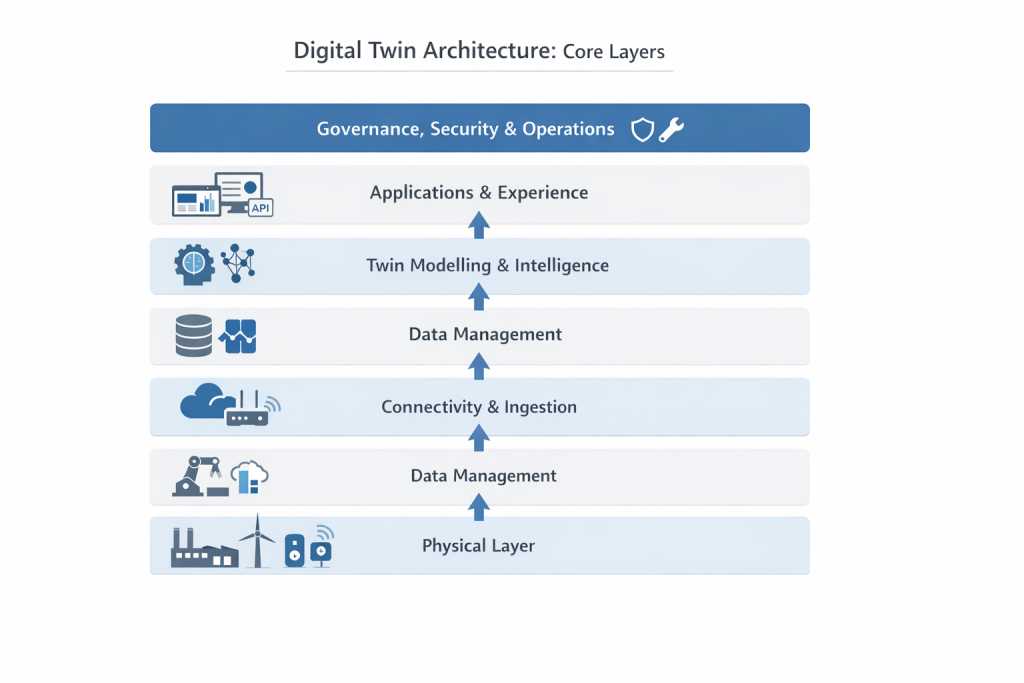
1. Physical layer
This is the real-world system: machines, vehicles, buildings, production lines, utilities, medical devices, or infrastructure.
The architecture starts here because the twin can only be as useful as the asset context it receives. Telemetry alone is not enough. You also need information such as asset identity, hierarchy, configuration, maintenance history, operating limits, and environment.
For example, temperature data from a motor means little without context. Is the motor under full load? Was a component replaced last week? Is ambient temperature unusually high? Is the sensor mounted consistently across the fleet? Architecture decisions often fail when teams underestimate how much context the twin needs to interpret raw signals correctly.
2. Connectivity and ingestion layer
This layer moves data from the physical environment into the digital system.
Typical inputs include:
- IoT sensor streams
- PLC and SCADA feeds
- MES and historian data
- ERP and maintenance records
- CAD, BIM, or engineering models
- manual inspection data
- service logs
- external data such as weather, traffic, or grid conditions
The real issue is not just connecting these sources. It is handling differences in protocol, reliability, frequency, semantics, and ownership.
In industrial settings, you may deal with OPC UA, Modbus, MQTT, proprietary gateways, and legacy systems that were never designed for open integration. In enterprise environments, the challenge shifts towards APIs, master data mismatches, and delayed batch updates.
Architecturally, this layer needs to support:
- secure device and system connectivity
- buffering and retry logic
- timestamp normalisation
- schema validation
- edge filtering where bandwidth or latency matters
- source-level data quality checks
If this layer is weak, everything above it becomes fragile. A sophisticated model will not rescue poor ingestion discipline.
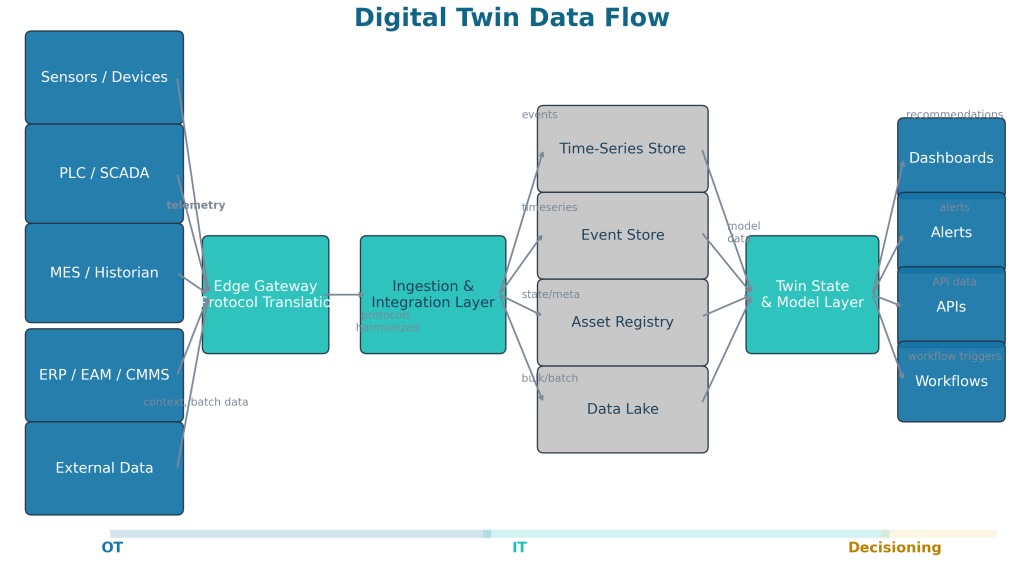
3. Data management layer
This is where the architecture begins to separate useful twins from data aggregation projects.
The twin needs a coherent representation of entities, states, relationships, and time. That usually means combining multiple storage and processing styles rather than forcing everything into one repository.
Common data responsibilities include:
- time-series storage for telemetry
- event storage for state changes and alarms
- master and reference data for asset definitions
- graph or relationship modelling for asset topology
- document or object storage for engineering artefacts
- historical snapshots for replay and audit
- metadata management and lineage
A digital twin is not simply a dashboard on top of time-series data. It depends on identity and relationships. Which sensor belongs to which subassembly? Which assets are part of the same line? Which configuration version was active when performance degraded? Which downstream system consumed the model output?
That sounds manageable in a proof of concept. At enterprise scale, it becomes one of the hardest parts of the architecture.
Why the asset model matters so much
The asset model is the structural backbone of the twin. It defines what entities exist, how they relate to each other, what properties they have, and what states are meaningful.
Without a disciplined asset model, teams end up with fragmented twins:
- one model in the IoT platform
- another in the ERP system
- another in the maintenance application
- a fourth in analytics notebooks
Once that happens, trust erodes quickly. Different teams see different versions of the same asset. Root-cause analysis becomes slower. Fleet comparison becomes unreliable. Automation becomes risky.
This is why digital twin architecture is often as much an information architecture problem as a systems integration problem.
4. Twin modelling and intelligence layer
This is the part most people think of first, but it sits on top of a larger foundation.
The twin modelling layer maintains the digital representation of the asset or system and updates it based on incoming data, rules, and models. Depending on the use case, this can include:
- state models
- rules engines
- statistical models
- machine learning models
- physics-based simulations
- hybrid models that combine physics and data-driven methods
- scenario analysis logic
- optimisation routines
The right choice depends on the decision you are trying to support.
If you need simple condition monitoring, rules and thresholds may be enough. If you are estimating remaining useful life, you may need probabilistic or machine learning models. If you are simulating equipment behaviour under changing loads, physics-based modelling may be more credible.
The trade-off is straightforward: more sophisticated models can produce better insight, but they demand better data, stronger calibration, deeper domain expertise, and more maintenance.
Static model, dynamic model, and operational state
A practical twin usually combines three types of information:
Static model:
Relatively stable properties such as design specifications, asset hierarchy, and installed components.
Dynamic model:
Current and changing values such as temperature, vibration, throughput, location, or utilisation.
Operational state:
Derived interpretation such as healthy, overloaded, idle, maintenance due, anomaly detected, or efficiency below target.
The architecture should keep these concerns distinct. Mixing them carelessly makes model updates harder and audit trails weaker.
5. Application and experience layer
This is where the twin becomes useful to humans and other systems.
Typical outputs include:
- dashboards and visualisation
- operational alerts
- maintenance recommendations
- simulation views
- what-if planning tools
- API services for downstream applications
- workflow triggers into enterprise systems
A common mistake is to overinvest in visual sophistication and underinvest in operational fit. A 3D twin may look compelling in a demo, but if maintenance planners need a work queue and probability score, then a cinematic interface is not the point.
From a decision-maker’s perspective, the twin succeeds only when it changes action. That means the application layer should align with existing operating workflows. If the twin detects a probable failure but does not connect to the maintenance planning process, value leaks out.
6. Governance, security, and operations layer
This layer is often treated as a later-stage concern. That is a mistake.
Digital twins combine operational technology, enterprise data, engineering models, and in some cases control decisions. The governance burden is therefore significant.
This layer typically includes:
- identity and access control
- device authentication
- network security between edge and cloud
- model versioning
- data retention policies
- audit trails
- approval workflows for model changes
- observability for pipelines and model performance
- backup and recovery planning
- compliance requirements where relevant
At scale, operating the twin becomes its own discipline. Models drift. Devices fail. Schemas change. Reference data breaks joins. Alerts become noisy. Teams change vendors. A production-grade architecture expects this and designs for maintainability rather than assuming stable conditions.
Common architectural patterns
There is no single correct digital twin architecture. The right pattern depends on latency, autonomy, network reliability, regulatory constraints, and economic value.
Still, a few patterns show up repeatedly.
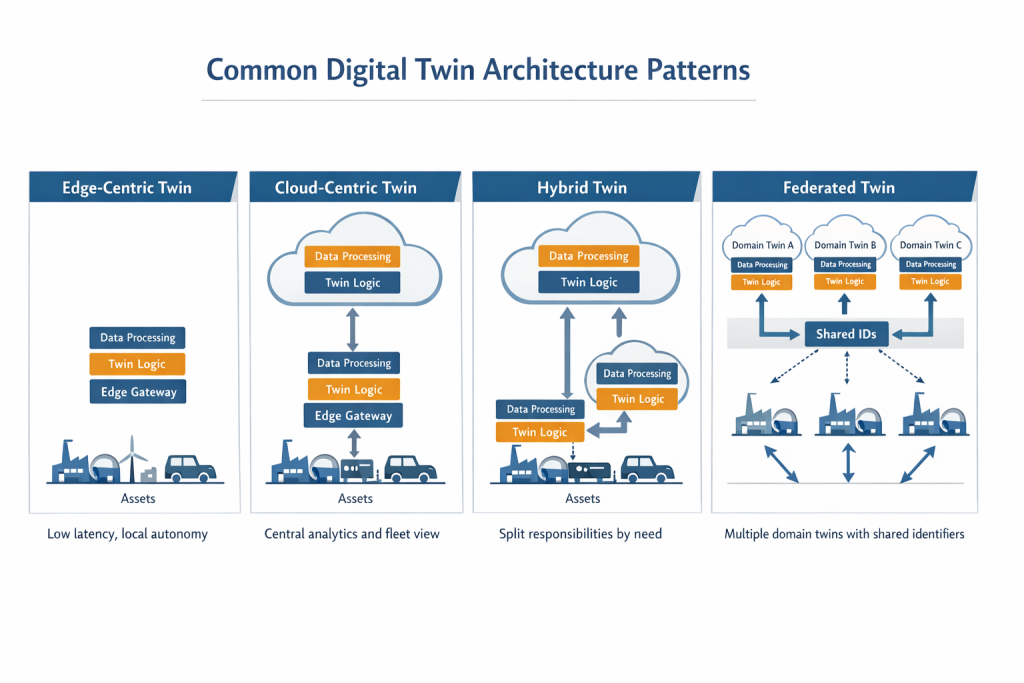
Edge-centric twin
In this pattern, a meaningful part of the twin runs close to the asset, often on-site or on-device. This is common where latency matters, connectivity is intermittent, or data volume is too high to send upstream continuously.
It is useful for:
- industrial control environments
- remote infrastructure
- safety-sensitive monitoring
- local anomaly detection
The advantage is faster response and lower dependency on cloud connectivity. The trade-off is harder lifecycle management. Distributed edge deployments are operationally demanding, especially when model updates, patching, and observability are inconsistent.
Cloud-centric twin
Here, most twin logic, storage, and analytics run in the cloud, with the edge handling collection and forwarding.
It is useful for:
- fleet visibility
- cross-site comparison
- historical analysis
- model training
- enterprise integration
This pattern simplifies central governance and scaling of analytics, but it can create problems where local latency or network resilience matters. It also raises ongoing cost questions around data transport and storage.
Hybrid twin
This is the pattern most serious deployments end up using.
Operational filtering, control-adjacent logic, or quick local decisions stay at the edge. Aggregation, model training, fleet analytics, and enterprise orchestration happen centrally.
That sounds reasonable, but the boundary must be defined carefully. Teams often say “hybrid” when they really mean “we have not yet decided where responsibilities belong”. A good hybrid architecture is explicit about:
- what must happen locally
- what can tolerate delay
- how models are synchronised
- what happens during disconnection
- which system is authoritative for each state
Federated twin
This pattern appears in large enterprises where no single platform can own the entire twin. Different domains maintain domain-specific twins or digital representations, connected through shared identifiers, events, and governance standards.
You see this in complex manufacturing, smart cities, utilities, aerospace, and infrastructure ecosystems.
The benefit is organisational realism. Teams can evolve domain models without forcing one monolithic architecture. The downside is integration complexity. Federation only works when identity, semantics, and event contracts are governed properly.
Core design decisions that shape the architecture
The technology stack matters, but a few design decisions matter more.
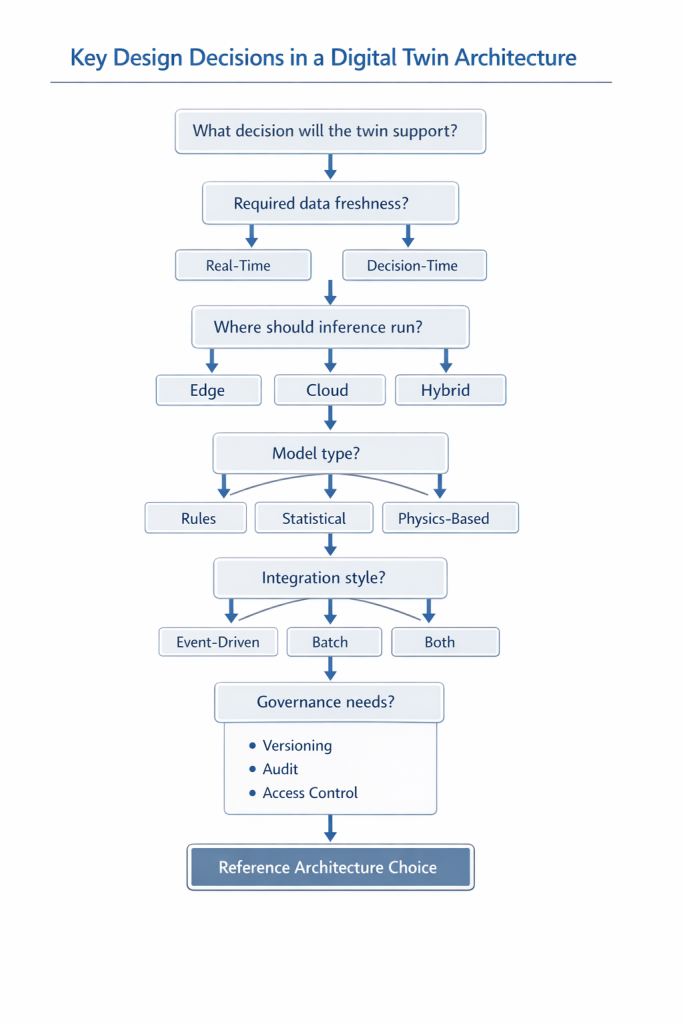
Real-time versus decision-time
Not every twin needs real-time architecture.
Many teams ask for streaming by default because it sounds advanced. In reality, the requirement is often decision-time, not real-time. If a maintenance planner reviews the asset every four hours, second-by-second updates may add cost without adding value.
This distinction affects everything:
- network design
- storage cost
- processing complexity
- alert strategy
- edge requirements
Use the minimum freshness that supports the decision.
Event-driven versus batch-oriented processing
Event-driven designs are useful when state changes, alerts, and operational triggers matter. Batch-oriented processing suits periodic analytics, fleet benchmarking, and long-window optimisation.
Most twin architectures need both. The key is not to force one model onto all workloads. Streaming pipelines handle immediacy well, but they are harder to debug and govern. Batch pipelines are simpler, but they can miss operational windows.
Canonical data model versus bounded context models
A central canonical model feels attractive because it promises consistency. At scale, it can become slow to change and politically difficult to govern.
Bounded context models are more flexible. Each domain keeps a model suited to its needs, with mapping between contexts. This is often more realistic, especially in large enterprises. The trade-off is higher integration discipline.
For most organisations, a hybrid approach works better: shared core identifiers and governance, with domain-specific extensions.
Build the twin platform or assemble it
Some organisations want a single digital twin platform. Others assemble capabilities from IoT, data, analytics, GIS, BIM, simulation, and enterprise systems.
A platform-first approach can improve consistency, but it risks forcing all use cases into the same model. An assembled approach can fit reality better, but it increases architecture and integration burden.
The right answer depends on the spread of use cases and the maturity of internal engineering teams. If your organisation struggles to maintain standard data contracts, assembling a highly composable twin stack may create more fragility than flexibility.
Data quality problems that break digital twins
Digital twin architecture discussions often focus on models and visualisation. In practice, data quality causes more damage.
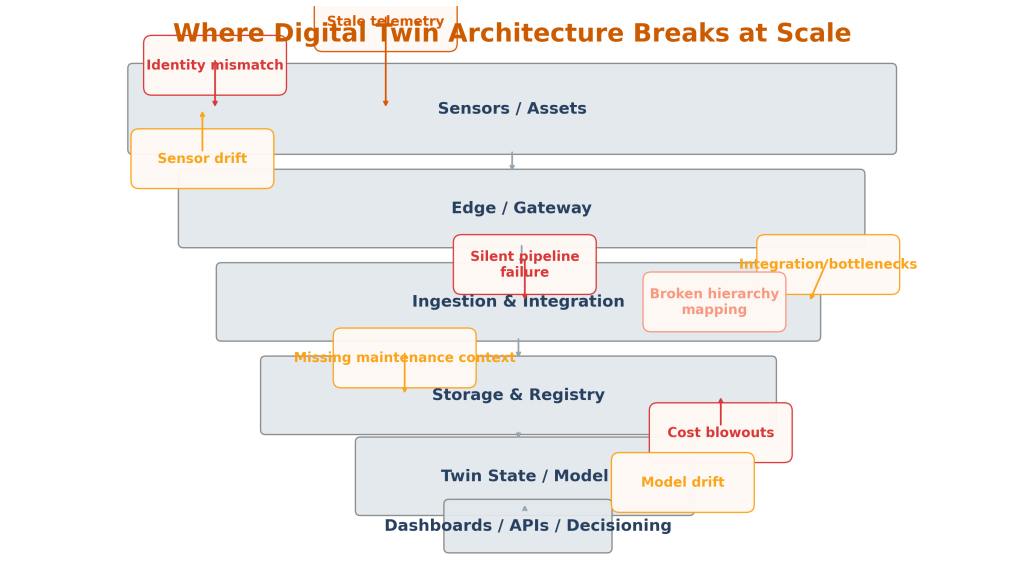
Typical failure modes include:
Identity mismatches
The same asset appears under different IDs across OT, ERP, and service systems. That breaks correlation and historical continuity.
Timestamp inconsistency
Different systems use different clocks, time zones, or transmission delays. Sequence reconstruction becomes unreliable.
Sensor drift and calibration issues
The model assumes data accuracy that the field environment does not support.
Missing context
A signal is present, but operating mode, maintenance event, or configuration change is absent.
Inconsistent hierarchy
An asset’s place in a plant, line, building, or network changes, but the digital model is not updated cleanly.
Silent pipeline failure
Data ingestion drops or degrades without strong observability. The twin appears healthy while its state is stale.
A mature architecture treats these as expected conditions, not exceptions.
The role of simulation in digital twin architecture
Simulation is important, but not every twin needs a full simulation engine.
There are broadly three levels:
- Descriptive twin – reflects current and historical state
- Predictive twin – estimates future condition or likely outcomes
- Prescriptive twin – suggests actions or optimised settings
Simulation becomes more valuable as you move from descriptive to predictive and prescriptive use cases. But it also raises the bar for model fidelity, compute requirements, and validation discipline.
For example, a building energy twin may benefit from scenario simulation because occupancy, weather, and equipment interactions matter. A simple pump-health twin may deliver value without heavy simulation at all.
The mistake is to assume that “real twin” means “high-fidelity simulation”. Often it means the opposite: a narrower, decision-focused model that operations teams can trust.
Enterprise integration: where architecture meets organisational reality
A digital twin becomes strategically useful when it connects to operating systems, not when it sits beside them.
That usually means integration with some combination of:
- ERP
- EAM or CMMS
- MES
- PLM
- SCADA
- historian platforms
- CRM or field service systems
- GIS or BIM tools
- workflow and ticketing systems
This is where architecture meets organisational friction. Data ownership is fragmented. Change windows are limited. Legacy systems may have poor interfaces. Cybersecurity teams may restrict connectivity. Operations teams may resist automated recommendations if the logic is opaque.
A sound architecture does not assume clean integration pathways. It stages them. In many cases, read-only integration is the right first step. Closed-loop action can come later, after trust and governance improve.
Scaling from pilot to production
Many digital twins look promising in a pilot because the environment is controlled. Data is hand-curated, stakeholders are engaged, and edge cases are ignored. Production is different.
At scale, you need to handle:
- thousands or millions of events
- changing asset configurations
- onboarding of new sites
- multiple firmware versions
- varying sensor quality
- model retraining or recalibration
- support processes for broken data flows
- cost control for storage and computation
The architecture that works for ten assets may collapse under ten thousand if identity, metadata, tenancy, and lifecycle management are weak.
A useful question is this: what becomes harder each time you add another asset class, site, or integration? The answer usually points to the architectural bottleneck.
A practical reference architecture
For most enterprise-grade use cases, a workable digital twin architecture tends to include the following:
At the edge
- device connectivity and protocol translation
- local buffering
- filtering and compression
- limited state evaluation or rule execution
- secure communication to central systems
In the integration layer
- ingestion services for streaming and batch inputs
- schema checks
- metadata enrichment
- event routing
- source-specific adapters
In the data and model layer
- time-series store
- asset registry and master data
- relationship or graph model where needed
- historical store or data lake
- twin state service
- model serving and version management
In the application layer
- operations dashboard
- alerting and notification
- simulation or scenario interface where needed
- APIs for enterprise systems
- workflow integration
In the governance layer
- IAM and role-based access
- audit logging
- data quality monitoring
- lineage tracking
- model governance
- operational monitoring
This is still only a reference shape. The actual architecture should reflect the use case and constraints, not a vendor blueprint.
Questions to settle before you design
If you are defining a digital twin architecture, these questions are worth settling early:
- What operational or business decision will the twin improve?
- What is the minimum model fidelity needed for that decision?
- Which data sources are mandatory, and which are optional later?
- What freshness does the use case actually require?
- What happens when data is delayed, partial, or wrong?
- Which system is authoritative for asset identity and hierarchy?
- Where should inference happen: edge, cloud, or both?
- How will model versions be governed and audited?
- How will the twin connect to existing workflows?
- What is the plan to scale beyond the pilot?
These questions are more valuable than starting with a technology shortlist.
Where digital twin architecture creates real value
The architecture is justified when it helps an organisation make better decisions about physical systems with enough speed and confidence to change outcomes.
That value usually shows up in areas such as:
- reduced downtime
- better maintenance timing
- improved throughput
- lower energy consumption
- safer operations
- better remote support
- faster root-cause analysis
- stronger feedback from operations into design and service
But value does not come from the word “twin”. It comes from disciplined architecture choices: clear scope, credible models, usable workflows, and governance that survives real operations.
Final thought
A digital twin is not a single product and not a visual layer added to sensor data. It is an architectural approach for linking physical reality, digital context, and decision logic.
The hard part is not drawing the twin. The hard part is deciding what should be represented, what level of truth is good enough, and how the representation will stay trustworthy as systems, data, and operations change.
Teams that get this right usually start smaller than expected, model more carefully than expected, and integrate more selectively than expected. That restraint is often the difference between a pilot that impresses people and a production system that people actually use.